|
Jialuo Li I am a first-year graduate student in Computer Science at the Georgia Institute of Technology, where I am advised by Prof. Humphrey Shi. I received my undergraduate degree from the Institute for Interdisciplinary Information Sciences (IIIS), Tsinghua University (also known as the Yao Class, directed by Turing Award laureate Andrew Chi-Chih Yao). Previously, I interned at New York University, where I was advised by Prof. Saining Xie. Email / CV / Google Scholar / Twitter / Github |

|
|
Humans exhibit an extraordinary capacity to integrate information from multiple sensory modalities, such as vision, auditory, and tactile inputs, to navigate and interpret their environments with remarkable efficiency. This multimodal integration leverages the complementary strengths of each sensory channel, facilitating a coherent and comprehensive understanding of complex surroundings. Inspired by this cognitive prowess, my long-term objective is to develop AI systems that emulate human-like multimodal synthesis, thereby enhancing robustness and adaptability in both generative and understanding tasks. Specifically, I focus on multimodal generative models, ranging from text-to-image synthesis to Multimodal Large Language Models (MLLMs) and unified models. |
|
|

|
DuoGen: Towards General Purpose Interleaved Multimodal Generation
Min Shi, Xiaohui Zeng, Jiannan Huang, Yin Cui, Francesco Ferroni, Jialuo Li, Shubham Pachori, Zhaoshuo Li, Yogesh Balaji, Haoxiang Wang, Tsung-Yi Lin, Xiao Fu, Yue Zhao, Chieh-Yun Chen, Ming-Yu Liu, Humphrey Shi CVPR 2026 (Highlight) Paper / Project Page DuoGen enables general-purpose interleaved multimodal generation by fusing a pretrained MLLM with a video-pretrained DiT. Leveraging a curated 298k-sample dataset, DuoGen significantly outperforms open-source baselines in visual fidelity and consistency and achieves performance comparable to Nano-banana. |
|
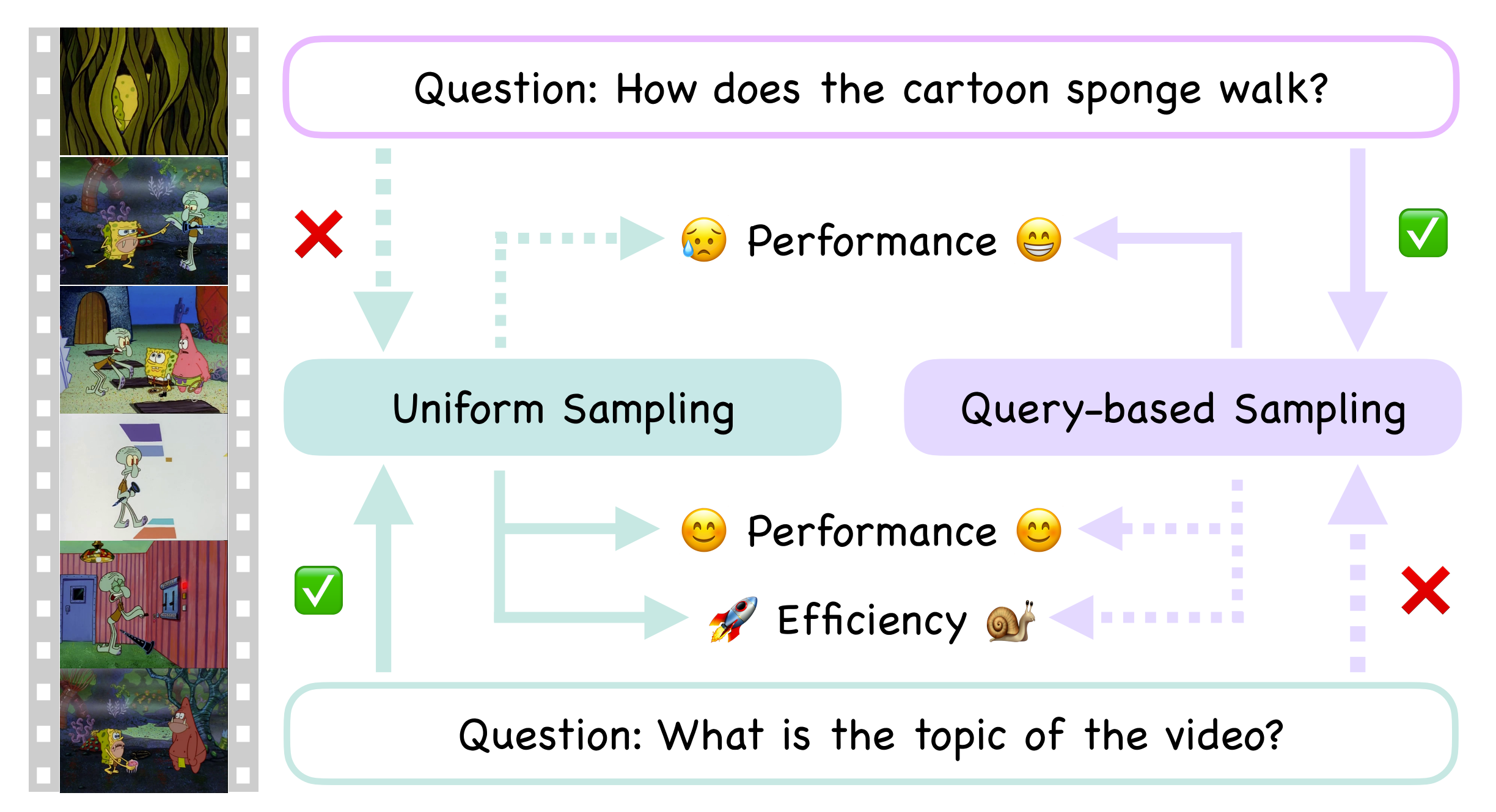
Divide, then Ground: Adapting Frame Selection to Query Types for Long-Form
Video Understanding
Jialuo Li, Bin Li, Jiahao Li, Yan Lu CVPR 2026 Paper / Code DIG optimizes long-form video understanding by distinguishing between "global" and "localized" queries, applying different strategies for each with a training-free approach. |

|
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with
Reinforcement Learning
Jitesh Jain, Jialuo Li, Zixian Ma, Jieyu Zhang, Chris Dongjoo Kim, Sangho Lee, Rohun Tripathi, Tanmay Gupta, Christopher Clark, Humphrey Shi CVPR 2026 Project Page / Paper / Dataset / Code SAGE introduces a human-inspired agentic framework that replaces resource-heavy frame processing with iterative reasoning and a diverse toolkit for efficient long video understanding by leveraging a novel synthetic data pipeline and a specialized RL strategy. |
|
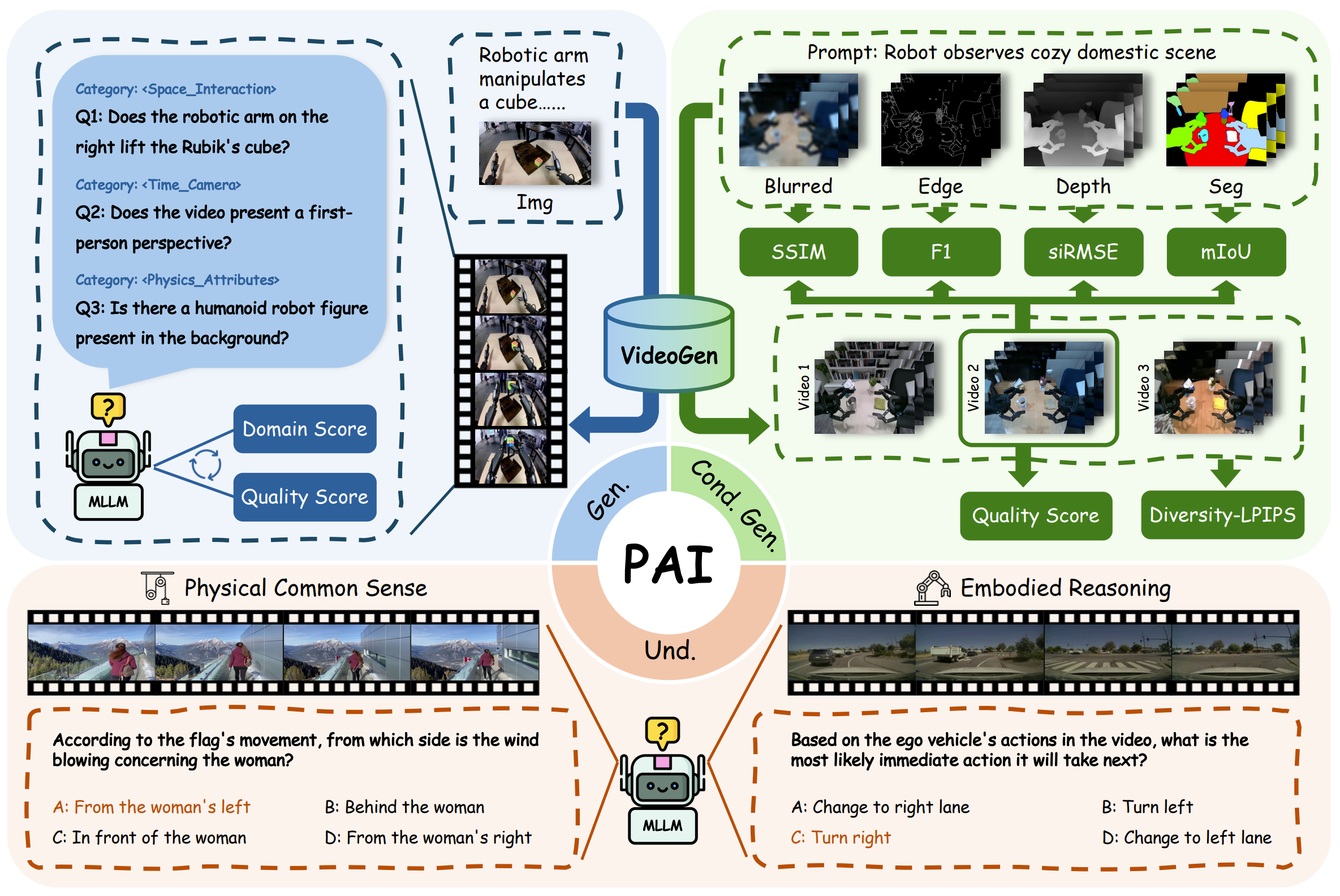
PAI-Bench: A Comprehensive Benchmark For Physical AI
Fengzhe Zhou*, Jiannan Huang*, Jialuo Li*, Deva Ramanan, Humphrey Shi CVPR 2026 (Oral) Paper / Dataset / Code PAI-Bench is a new benchmark designed to evaluate Physical AI capabilities across video generation and understanding. The study finds that while current models produce high-quality visuals, they lack the physical common sense and reasoning required to truly understand real-world dynamics. |

|
Science-T2I: Addressing Scientific Illusions in Image Synthesis
Jialuo Li, Wenhao Chai, Xingyu Fu, Haiyang Xu, Saining Xie CVPR 2025 Project Page / Paper / Dataset / Code / Poster We introduce SciScore, a reward model that improves generative models' scientific accuracy. Trained in two stages, it achieves human-level performance in evaluating scientific image realism on Science-T2I dataset. |
|
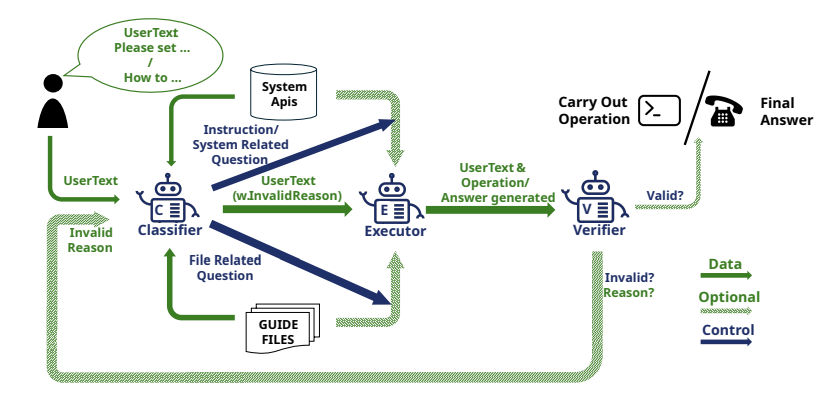
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Jingzhe Shi, Jialuo Li, Qinwei Ma, Zaiwen Yang, Huan Ma, Lei Li COLM 2024 Project Page / Paper CHOPS uses small and large LLMs to create an efficient, safe LLM agent that accesses user data, interacts with systems, and delivers accurate responses. |
|
Georgia Institute
of Technology
2025.08 - Present Graduate Student Research Advisor: Prof. Humphrey Shi |
|
|
Microsoft Research Lab - Asia
2024.09 - 2025.06 Research Intern Research Advisor: Dr. Bin Li |
|
|
New York
University
2024.02 - 2025.02 Research Intern Research Advisor: Prof. Saining Xie |
|
|
Tsinghua
University
2021.09 - 2025.06 Undergraduate Student Research Advisor: Prof. Li Yi. |
|
|
|
This homepage is designed based on Jon Barron's homepage and
deployed on GitHub Pages. Last updated: Jan 21, 2026.
|